2026-04-21
The Missing Half of MCP

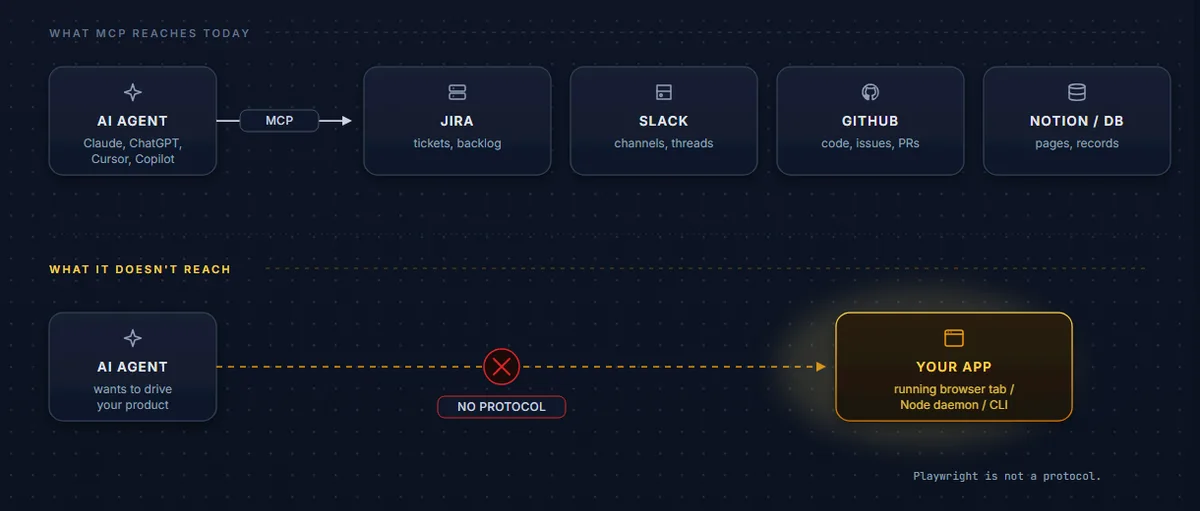
MCP gave AI agents a way to reach your systems of record. Jira, Slack, GitHub, Notion, your data warehouse. As of April 2026, that part of the stack works well and keeps getting better.
What MCP doesn’t reach is live applications. The web app running in a tab, the desktop tool the user just launched, the CLI spinning up a local daemon. Anywhere the state lives in a running process and the surface you actually want the AI to touch isn’t a REST endpoint but the same handlers your UI already calls when a user clicks a button.
Right now, the options for letting an AI agent drive that kind of application look like this:
- Browser automation. Hand the agent Playwright or Anthropic Computer Use and let it scrape the DOM, click buttons, hope the UI hasn’t shifted.
- A REST API nobody designed for AI. Documented for humans, shaped for your frontend, and wrapped in a custom MCP server someone has to build and maintain.
- Just don’t. The AI stays on the outside. The app stays an island.
All three are bad. That’s the gap I’ve been stuck on, and recently I’ve been building a fix. It’s called Tesseron, it’s open source, it hit v1.0 last week, and I want to explain what it does and why it needs to exist.
What MCP Actually Solved
To understand what’s missing, start with what works.
MCP (the Model Context Protocol) is, by any honest measure, the most successful open standard AI has produced. As of April 2026, there are 10,000+ public MCP servers, 97 million monthly SDK downloads, and every major AI vendor supports it. The pitch is simple: before MCP, M models times N tools meant M × N custom integrations. MCP collapsed that to M + N.
But notice where MCP lives.
MCP is built for AI pulling context from systems of record over stable HTTP APIs. Jira. Notion. GitHub. Salesforce. Google Drive. Your data warehouse. Read-heavy. Published connectors maintained by somebody else, running on someone’s server, holding someone’s data.
That covers an enormous amount of AI-useful work. But it leaves one whole category almost entirely uncovered: live applications.
A browser tab running a React frontend. A desktop app (Electron, Tauri, native) the user just launched. A Node daemon holding domain objects in memory. A CLI sitting in a terminal. None of those have a published connector. None have a stable HTTP API a connector could wrap. Their state lives in a process the user just started, in a window they can see, in front of them right now. And the surface the AI should be able to touch isn’t GET /todos, it’s the same handler the UI already calls when the user clicks a button. The handler that enforces your business rules, emits the right side effects, and updates state the user is watching live.
MCP doesn’t reach that. It wasn’t designed to.
Why Browser Automation Isn’t the Answer
The reflexive response is “well, just use Playwright then” or “use Anthropic Computer Use.” Let the model drive a browser, click the buttons, and fill the forms.
I’ve shipped products that do this. I don’t recommend it.
It’s slow. Every action is a roundtrip through a screenshot, a model call, and DOM reasoning. Something that should take 50 ms takes 8 seconds.
It’s brittle. A CSS rename, a lazy-loaded modal, an A/B test that moves a button, and the agent’s entire workflow breaks. Your frontend team ships their normal work and the AI integration silently regresses.
It fights your app. The agent sees the rendered DOM, not your domain model. It has no concept of your Todo, your Invoice, your Deployment. It gropes through a visual representation of your state when your state already exists, typed and structured, one function call away.
It can’t really ask questions. Your handler needed a confirmation. Your handler needed the user to pick from five options. In DOM-automation land, that’s another round of scraping a modal you hope opened.
It has no access to your business logic. The handler that enforces “users on the free plan can’t delete more than 10 items per day” lives in your code. The agent running Playwright just clicks the delete button ten times and gets surprised when the eleventh one 403s.
The whole model is backwards. You wrote the handler. The handler knows the rules. You want the AI to call the handler, not reverse-engineer the UI the handler renders.
What I Actually Wanted
The shape I kept drawing on whiteboards was this:
- The app runs normally. React browser app, Svelte, Vue, an Electron or Tauri desktop app, a Node daemon, a CLI. The runtime doesn’t matter.
- Inside the app, I register a typed action the same way I’d register a route.
- The action has a schema for input, a real handler, and optionally a schema for its output.
- When an AI agent invokes that action, my actual handler runs. Against my actual state. Returning my actual domain objects. Same code path the UI uses.
- And the handler can talk back to the agent. Ask yes-or-no, ask for a structured form, stream progress, even call the agent’s LLM mid-handler.
In other words, a first-class AI port for applications. The way an app opens an HTTP port for browsers, it should open an MCP port for agents. Same handlers, different callers.
That’s what Tesseron is: a protocol, plus the SDKs that implement it.
The Shape

Here’s the architecture.
- Your app pulls in one of the SDKs and registers actions and resources using a fluent Zod-style builder. As of v1.0, the available SDKs are JavaScript/TypeScript:
@tesseron/webfor browsers,@tesseron/serverfor any Node process (daemon, CLI, HTTP server, Electron main process),@tesseron/reactfor hooks. More languages are planned; the protocol spec is language-neutral by design and separately licensed so anyone can implement a compatible SDK. - The MCP gateway (
@tesseron/mcp) is a small local binary. It listens onws://127.0.0.1:7475for connections from your app and speaks MCP stdio to the agent. - The MCP client (Claude Code, Claude Desktop, Cursor, Copilot, whatever) sees your actions as native MCP tools. The gateway dynamically registers them at connection time.
The user types claim session XXXX-XX in their agent once (the app shows a six-character code). From then on, every action invocation the agent makes runs your real handler against your real state.
No browser automation. No scraping. No custom REST API. Your domain model, your handlers, exposed typed to whatever AI client the user prefers.
What the Code Looks Like
Here’s a small browser example. This is the whole thing.
import { tesseron } from '@tesseron/web';
import { z } from 'zod';
tesseron.app({ id: 'todo_app', name: 'Todo App' });
tesseron
.action('addTodo')
.describe('Add a todo item to the list.')
.input(z.object({ text: z.string().min(1) }))
.handler(({ text }) => {
state.todos.push({ id: newId(), text, done: false });
render();
return { ok: true };
});
await tesseron.connect();Every invocation runs the handler, mutates the real state.todos array, calls the real render(), and returns a typed response to the agent. Same action, same code path whether the user clicked a button or the agent called the tool.
In React, it’s a hook:
useTesseronAction('addTodo', {
input: z.object({ text: z.string().min(1) }),
handler: ({ text }) => setTodos((t) => [...t, { id: crypto.randomUUID(), text, done: false }])
});In Node, it’s the same builder, wired into whatever daemon, CLI, or Express service you’re running. The examples/ directory ships the same todo app implemented in vanilla TS, React, Svelte, Vue, plain Node, and Express. Read any two side by side to see what the SDK abstracts and what stays idiomatic per stack.
The Handler Can Talk Back

This is the part that took the longest to get right, and it’s the part I’m most pleased with.
A handler isn’t just a function. It receives a ctx argument that lets it have a conversation with the agent’s user mid-execution.
tesseron
.action('deployService')
.input(
z.object({
service: z.string(),
env: z.enum(['staging', 'production'])
})
)
.annotate({ destructive: true, requiresConfirmation: true })
.handler(async ({ service, env }, ctx) => {
const ok = await ctx.confirm({ question: `Deploy ${service} to ${env}?` });
if (!ok) return { deployed: false };
ctx.progress({ message: 'Building...', percent: 10 });
await build(service);
ctx.progress({ message: 'Uploading...', percent: 60 });
await upload(service, env);
return { deployed: true };
});Four things happen there.
ctx.confirm pauses the handler and asks the user a yes/no question through the agent’s UI. The agent surfaces it as a proper confirmation prompt, not another model turn.
ctx.progress streams updates back to the agent while the handler is still running. The user sees “Building…” then “Uploading…” as it happens.
ctx.elicit (not shown) asks for structured input. You pass a Zod schema, the user fills a form, you get back a typed object.
ctx.sample (not shown) lets your handler call the agent’s LLM. This sounds small. It isn’t. It means your handler can ask “what’s the pithy release note for this diff” and get a real LLM completion back, without you shipping or paying for your own model.
Together these four are the difference between “a tool the AI can call” and “a handler that can actually participate in an AI-driven workflow.” The handler owns the flow. The agent is the substrate.
One Action, Two Callers

Here’s the part I didn’t expect to matter, but which ended up mattering a lot.
When you build an action in Tesseron, it’s just a function. You can also expose it over HTTP. The express-todo example shows this explicitly: same TodoStore, same addTodo action, available both as an MCP tool for Claude and as a REST endpoint for curl or your existing frontend.
const store = new TodoStore();
tesseron
.action('addTodo')
.input(z.object({ text: z.string() }))
.handler(({ text }) => store.add(text));
app.post('/todos', (req, res) => res.json(store.add(req.body.text)));Both channels mutate the same state. You don’t maintain two implementations. You don’t have to pick. The action is the surface; MCP and REST are two clients that call into it.
This matters for teams that already have an API and now want to add AI. You don’t rewrite the backend. You wrap the handler in a Tesseron action and let both callers route through it.
Why Open Source, and Why BUSL
Tesseron ships under the Business Source License 1.1. You can embed it in your app, run the gateway locally, fork it, redistribute it, sell software built with it. What you cannot do is offer Tesseron or a substantial portion of it as a hosted or managed service to third parties. After four years, each release auto-converts to Apache-2.0.
This is the same model HashiCorp used for Terraform. Sentry uses a similar scheme. It keeps the protocol open to self-hosters and product builders while reserving the commercial right to offer Tesseron-as-a-service.
The protocol spec itself is separately licensed under CC BY 4.0, so anyone can implement a compatible client or server in any language. That’s the part that needs to stay fully open for the ecosystem to work.
I’m aware source-available licenses are contentious. My read is that they’re the honest middle path. A pure MIT license would let any cloud provider take the implementation, run it as SaaS, and eat the upside. A pure proprietary license would kill adoption. BUSL keeps the code in the open where I want it and keeps one specific commercial door closed.
What’s Next
Tesseron is at v1.0.1 on npm, across five packages: SDKs for browser, Node, and React, plus the gateway. JavaScript and TypeScript is where it starts because that’s where most live-app surfaces happen to be as of April 2026, but the protocol itself is deliberately language-neutral. The wire format is JSON-RPC 2.0 over WebSocket, the capability model is mirrored from MCP, and the spec is published under CC BY 4.0 so anyone can implement a compatible client or server. The JS SDKs are the reference implementation, not the definition.
The protocol stays at 1.0.0, and I intend to keep it stable. Everything else is iteration.
The things I’m thinking about next, in rough order:
- Framework adapters for Svelte and Vue that mirror the
@tesseron/reactergonomics. The raw@tesseron/webAPI works fine in both today, but hooks are nicer. - A devtools UI served by the gateway at
/__devtools, so you can inspect claims, action invocations, and resource subscriptions without tailing logs. - A Python SDK so existing FastAPI or Django handlers can be exposed as Tesseron actions without rewriting them in TypeScript.
- Bindings for desktop-native runtimes (Rust for Tauri, maybe Swift / Kotlin) so a native desktop app can register actions the same way a browser tab does.
If you’re building any application that a user drives live, and you’re starting to think about how an AI agent fits into it, Tesseron is the thing I wish I’d had a year ago. It’s on npm, on GitHub, and the examples directory has six fully worked apps you can clone.
- Repo: github.com/kennyvaneetvelde/tesseron
- Docs: kennyvaneetvelde.github.io/tesseron
- npm:
@tesseron/web,@tesseron/server,@tesseron/react,@tesseron/mcp
If it’s useful, star the repo. If something is missing that you need, open an issue. I’ll be maintaining this going forward.